Large Language Models
Large Language Models (LLMs) are powerful pretrained text generation models capable of performing a number of advanced generative and predictives tasks with little to no addition training, including:
- Natural language understanding and response (e.g., chatbots, Q&A systems)
- Text completion (e.g., coding assistants)
- Text summarization
- Information extraction (e.g., document to table)
- Text classification
- Basic reasoning (e.g., agent-based systems)
With all these capabilities and various techniques being proposed to "customize" LLMs for specific datasets and tasks, it can be daunting to decide where to start. That's where Ludwig comes in!
Ludwig's LLM toolkit provides an easy customization ramp that let's you go from simple prompting, to in-context learning, and finally to full-on training and fine-tuning.
Customizing LLMs for Specific Tasks¶
There are many ways to modify or enhance LLMs to make them better at performing tasks. In Ludwig, we bucket these different techniques into two broad categories:
- Fine-Tuning, or modifying the weights of the LLM through a supervised learning process.
- In-Context Learning, or using additional task-specific context inserted into the prompt at inference time to steer the LLM toward performing a task.
The flowchart below visually presents a simplfiied decision-making process that can be used to decide which customization technique is right for you:
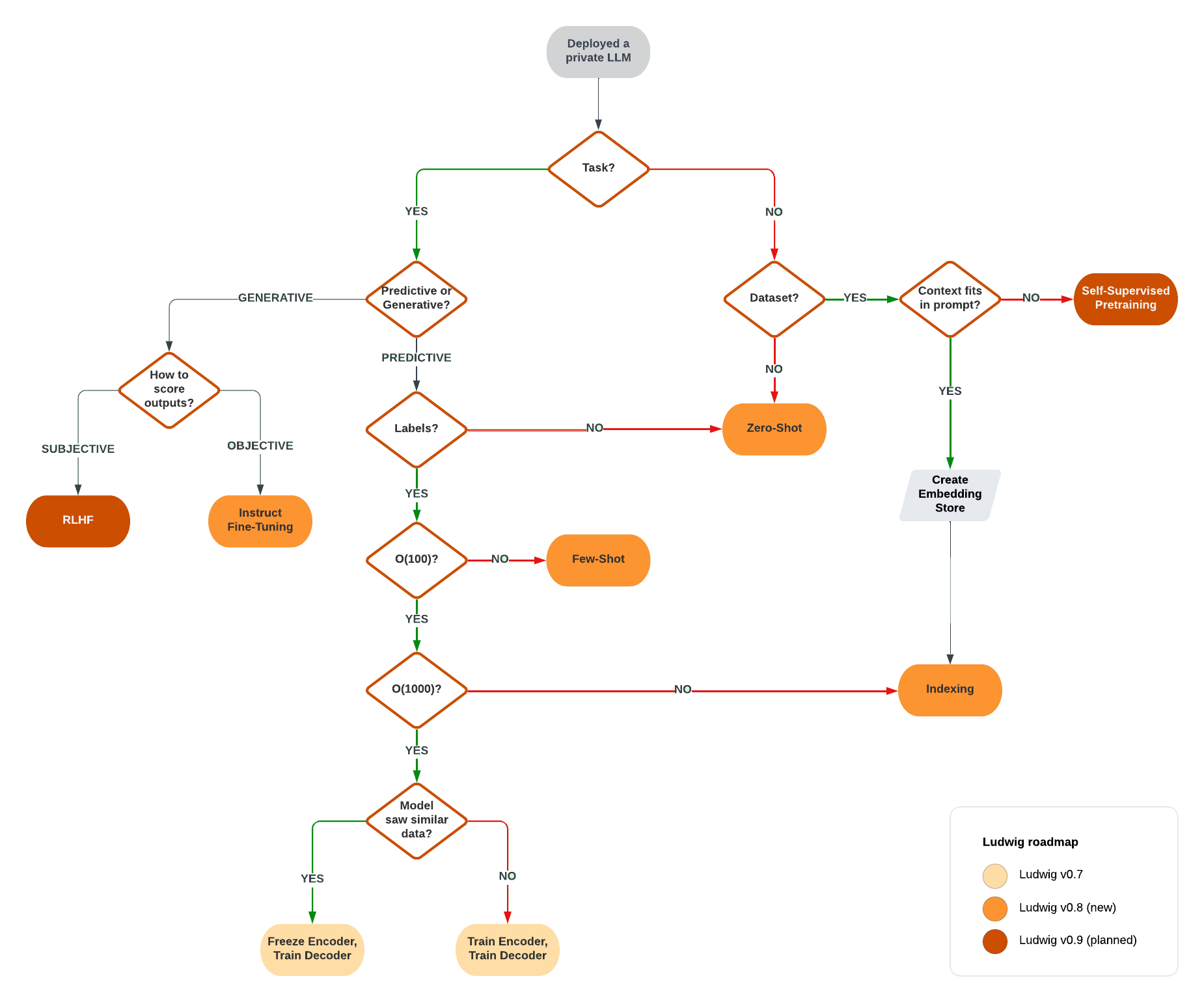
When to use Fine-Tuning¶
Fine-tuning is most commonly useful in the following situations:
- Instruction tuning, or taking an LLM that only generate text and adapting it to respond in a way that follows instructions, like a chatbot.
- Domain adaptation, for example, taking an LLM that responds in natural language and adapting it to generate structured output like JSON, source code, or SQL.
- Task adaptation, or taking a general-purpose LLM and specializing it to perform better a specific (usually predictive) task.
Fine-tuning generally requires on the order of a thousand to tens of thousans of labeled examples in order to be maximimally useful. As such, it's usually recommended to first see if in-context learning is sufficient to solve the problem before progressing to fine-tuning.
When to use In-Context Learning¶
In-context learning is most commonly useful in the following situations:
- Question answering on an internal corpus, where the LLM needs to respond factually in natural language.
- Few-shot text classification, or assigning labels to text when only a handful of ground truth examples are available.
- Retrieval-augmented generation, where an information retrieval process (often a text embedding model + a vector database) is used to insert semantic context into the prompt.
In-context learning doesn't require any training in order to make use of it, so it's a natural place to start when applying an LLM to a task. The primarily limitation of ICL is the context length of the LLM itself (how many "tokens" can be put into the prompt). It should be noted that even for models that accept very long contexts, there is often a degradation in performance as the prompt increases in length (see: Lost in the Middle: How Language Models Use Long Contexts). As such, if the the context needed to respond to the prompt is very large, it may be worth exploring fine-tuning instead.
Additional Topics¶
- VLM Fine-Tuning — Fine-tune Vision-Language Models (Qwen2-VL, LLaVA) on image+text tasks
- Multi-Adapter PEFT — Merge multiple LoRA adapters with TIES, DARE, or linear combining
- LLM Config Generation — Generate a valid Ludwig config from a plain-English task description
- Structured Output — Constrained decoding for guaranteed valid category and JSON output