Text Classification
This example shows how to build a text classifier with Ludwig.
These interactive notebooks follow the steps of this example:
- Ludwig CLI:

- Ludwig Python API:
We'll be using AG's news topic classification dataset, a common benchmark dataset for text classification. This dataset is a subset of the full AG news dataset, constructed by choosing the four largest classes from the original corpus. Each class contains 30,000 training samples and 1,900 testing samples. The total number of training samples is 120,000 with 7,600 total testing samples. The original split does not include a validation set, so we've labeled the first 5% of each training set class as the validation set.
This dataset contains four columns:
| column | description |
|---|---|
| class_index | An integer from 1 to 4: "world", "sports", "business", "sci_tech" respectively |
| class | A string, one of "world", "sports", "business", "sci_tech" |
| title | Title of the news article |
| description | Description of the news article |
Ludwig also provides several other text classification benchmark datasets which can be used, including:
Download Dataset¶
Downloads the dataset and write to agnews.csv in the current directory.
ludwig datasets download agnews
Downloads the AG news dataset into a pandas dataframe.
from ludwig.datasets import agnews
# Loads the dataset as a pandas.DataFrame
train_df, test_df, _ = agnews.load()
The dataset contains the above four columns plus an additional split column which is one of 0: train, 1: test,
2: validation.
Sample (description text omitted for space):
class_index,title,description,split,class
3,Carlyle Looks Toward Commercial Aerospace (Reuters),...,0,business
3,Oil and Economy Cloud Stocks' Outlook (Reuters),...,0,business
3,Iraq Halts Oil Exports from Main Southern Pipeline (Reuters),...,0,business
Train¶
Define ludwig config¶
The Ludwig config declares the machine learning task. It tells Ludwig what to predict, what columns to use as input, and optionally specifies the model type and hyperparameters.
Here, for simplicity, we'll try to predict class from title.
With config.yaml:
input_features:
-
name: title
type: text
encoder:
type: parallel_cnn
output_features:
-
name: class
type: category
trainer:
epochs: 3
With config defined in a python dict:
config = {
"input_features": [
{
"name": "title", # The name of the input column
"type": "text", # Data type of the input column
"encoder": {"type": "parallel_cnn"}, # The model architecture we should use for encoding this column
}
],
"output_features": [
{
"name": "class",
"type": "category",
}
],
"trainer": {
"epochs": 3, # We'll train for three epochs. Training longer might give
# better performance.
},
}
Create and train a model¶
ludwig train --dataset agnews.csv -c config.yaml
# Constructs Ludwig model from config dictionary
model = LudwigModel(config, logging_level=logging.INFO)
# Trains the model. This cell might take a few minutes.
results = model.train(dataset=train_df)
train_stats = results.train_stats
output_directory = results.output_directory
Evaluate¶
Generates predictions and performance statistics for the test set.
ludwig evaluate \
--model_path results/experiment_run/model \
--dataset agnews.csv \
--split test \
--output_directory test_results
# Generates predictions and performance statistics for the test set.
test_stats, predictions, output_directory = model.evaluate(
test_df, collect_predictions=True, collect_overall_stats=True
)
Visualize Metrics¶
Visualizes confusion matrix, which gives an overview of classifier performance for each class.
ludwig visualize \
--visualization confusion_matrix \
--ground_truth_metadata results/experiment_run/model/training_set_metadata.json \
--test_statistics test_results/test_statistics.json \
--output_directory visualizations \
--file_format png
from ludwig.visualize import confusion_matrix
confusion_matrix(
[test_stats],
model.training_set_metadata,
"class",
top_n_classes=[5],
model_names=[""],
normalize=True,
)
| Confusion Matrix | Class Entropy |
|---|---|
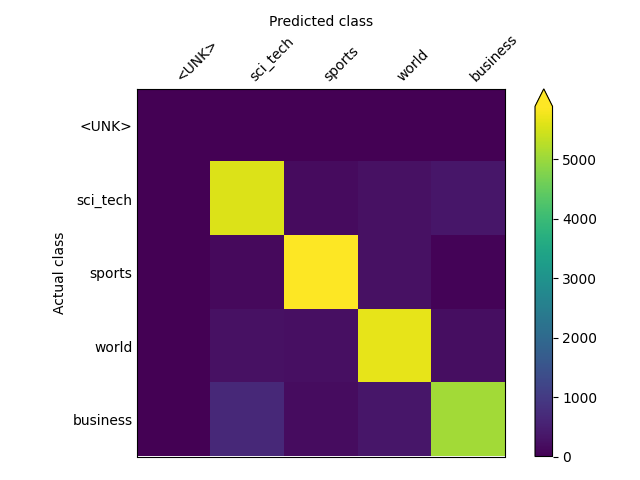 |
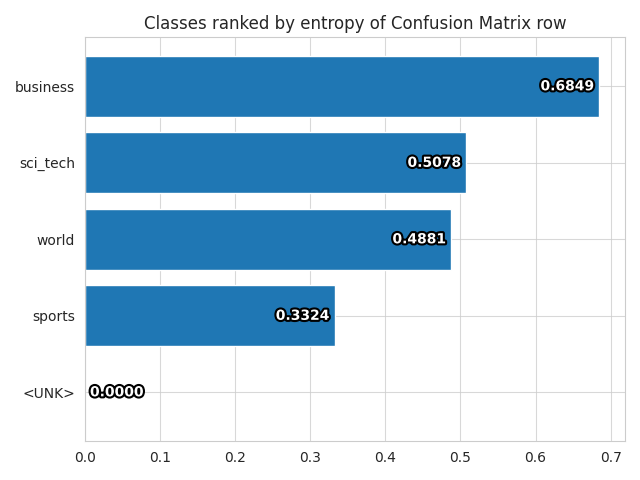 |
Visualizes learning curves, which show how performance metrics changed over time during training.
ludwig visualize \
--visualization learning_curves \
--ground_truth_metadata results/experiment_run/model/training_set_metadata.json \
--training_statistics results/experiment_run/training_statistics.json \
--file_format png \
--output_directory visualizations
# Visualizes learning curves, which show how performance metrics changed over
# time during training.
from ludwig.visualize import learning_curves
learning_curves(train_stats, output_feature_name="class")
| Losses | Metrics |
|---|---|
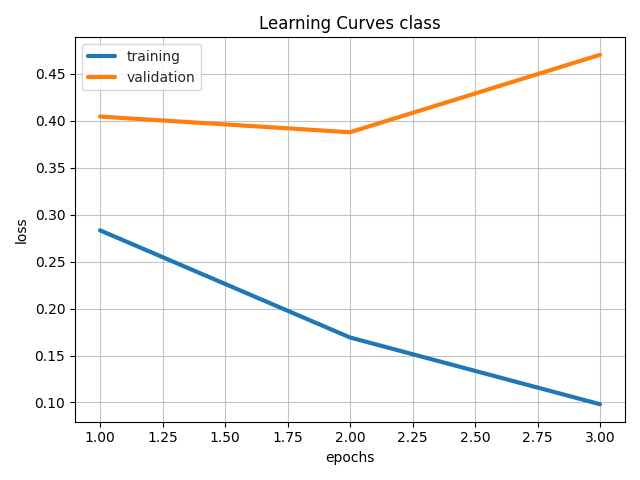 |
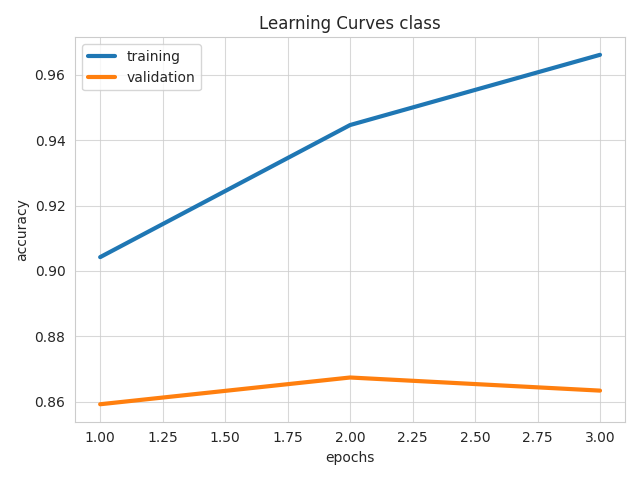 |
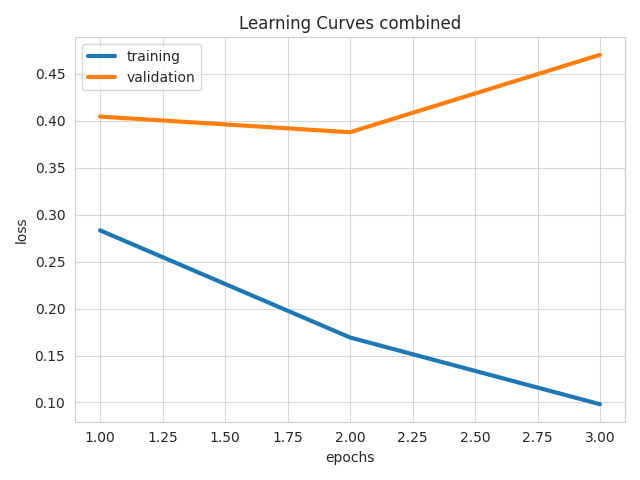 |
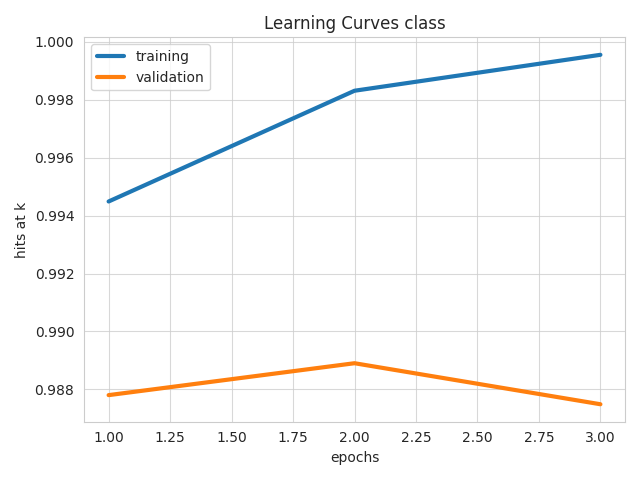 |
Make Predictions on New Data¶
Lastly we'll show how to generate predictions for new data.
The following are some recent news headlines. Feel free to edit or add your own strings to text_to_predict to see how the newly trained model classifies them.
With text_to_predict.csv:
title
Google may spur cloud cybersecurity M&A with $5.4B Mandiant buy
Europe struggles to meet mounting needs of Ukraine's fleeing millions
How the pandemic housing market spurred buyer's remorse across America
ludwig predict \
--model_path results/experiment_run/model \
--dataset text_to_predict.csv \
--output_directory predictions
text_to_predict = pd.DataFrame(
{
"title": [
"Google may spur cloud cybersecurity M&A with $5.4B Mandiant buy",
"Europe struggles to meet mounting needs of Ukraine's fleeing millions",
"How the pandemic housing market spurred buyer's remorse across America",
]
}
)
predictions, output_directory = model.predict(text_to_predict)
This command will write predictions to output_directory. Predictions outputs are written in multiple formats including
csv and parquet. For instance, predictions/predictions.parquet contains the predicted classes for each example as well
as the psuedo-probabilities for each class:
| class_predictions | class_probabilities | class_probability | class_probabilities_<UNK> | class_probabilities_sci_tech | class_probabilities_sports | class_probabilities_world | class_probabilities_business |
|---|---|---|---|---|---|---|---|
| sci_tech | [1.9864278277825775e-10, ... | 0.954650 | 1.986428e-10 | 0.954650 | 0.000033 | 0.002563 | 0.042754 |
| world | [8.458710176739714e-09, ... | 0.995293 | 8.458710e-09 | 0.002305 | 0.000379 | 0.995293 | 0.002022 |
| business | [3.710099008458201e-06, ... | 0.490741 | 3.710099e-06 | 0.447916 | 0.000815 | 0.060523 | 0.490741 |