How Ludwig Works
Configuration¶
Ludwig provides an expressive declarative configuration system for how users construct their ML pipeline, like data preprocessing, model architecting, backend infrastructure, the training loop, hyperparameter optimization, and more.
input_features:
-
name: title
type: text
encoder:
type: rnn
cell: lstm
num_layers: 2
state_size: 128
preprocessing:
tokenizer: space_punct
-
name: author
type: category
encoder:
embedding_size: 128
preprocessing:
most_common: 10000
-
name: description
type: text
encoder:
type: bert
pretrained_model_name_or_path: answerdotai/ModernBERT-base
-
name: cover
type: image
encoder:
type: resnet
num_layers: 18
output_features:
-
name: genre
type: set
-
name: price
type: number
preprocessing:
normalization: zscore
trainer:
epochs: 50
batch_size: 256
optimizer:
type: adam
beat1: 0.9
learning_rate: 0.001
backend:
type: local
cache_format: parquet
hyperopt:
metric: f1
sampler: random
parameters:
title.encoder.num_layers:
lower: 1
upper: 5
trainer.learning_rate:
values: [0.01, 0.003, 0.001]
See Ludwig configurations for an in-depth reference.
Data type abstractions¶
Every feature in Ludwig is described by a specific data type. Each data type maps to a specific set of modules that handle preprocessing, encoding, decoding, and post-processing for that type. Vice versa, every module (preprocessor, encoder, decoder) is registered to a specific set of data types that the module supports.
Read more about Ludwig's supported feature types.
ECD Architecture¶
Ludwig’s core modeling architecture is referred to as ECD (encoder-combiner-decoder). Multiple input features are encoded and fed through the Combiner model that operates on encoded inputs to combine them. On the output side, the combiner model's outputs are fed to decoders for each output feature for predictions and post-processing. Find out more about Ludwig's Combiner models like TabNet, Transformer, and Concat (Wide and Deep learning).
Visualized, the ECD architecture looks like a butterfly and sometimes we refer to it as the “butterfly architecture”.
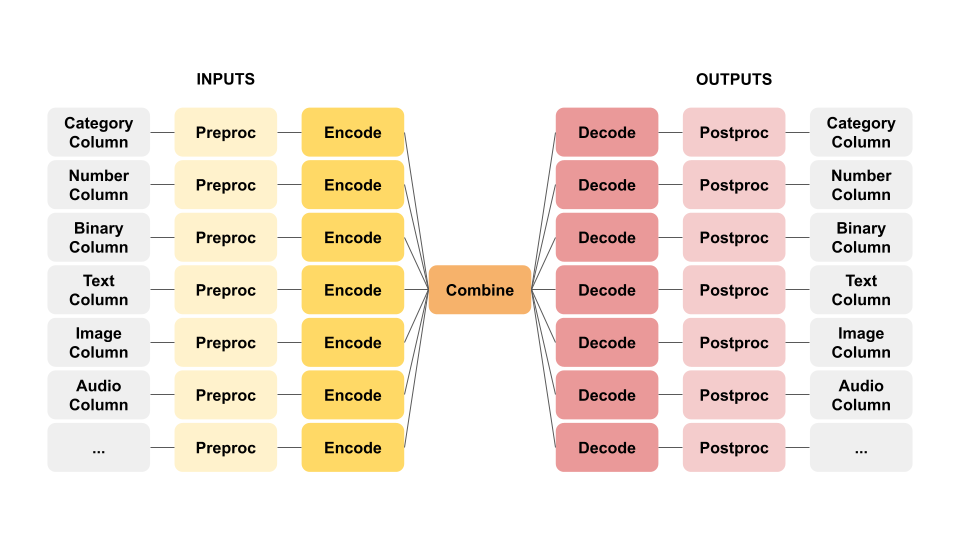
ECD flexibly handles many different combinations of input and output data types, making the tool well-suited for many different applications.
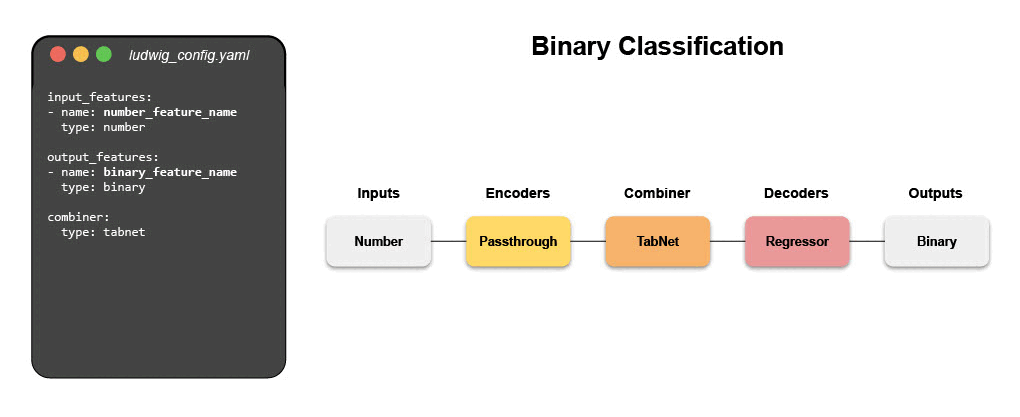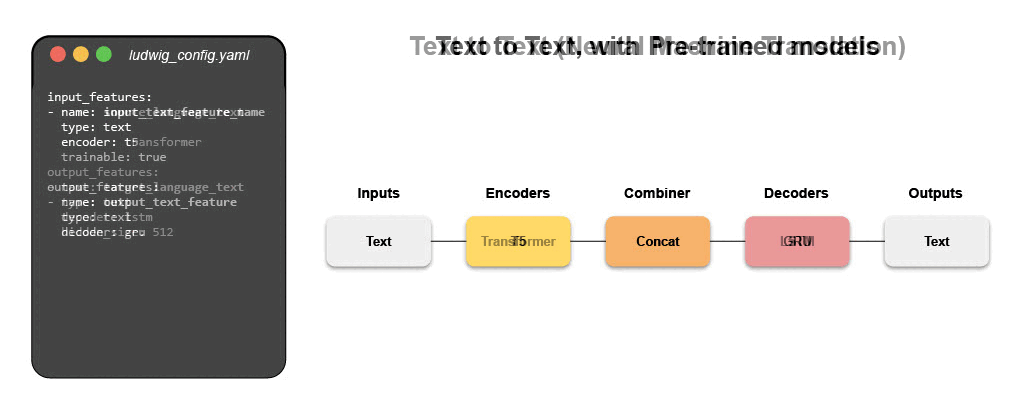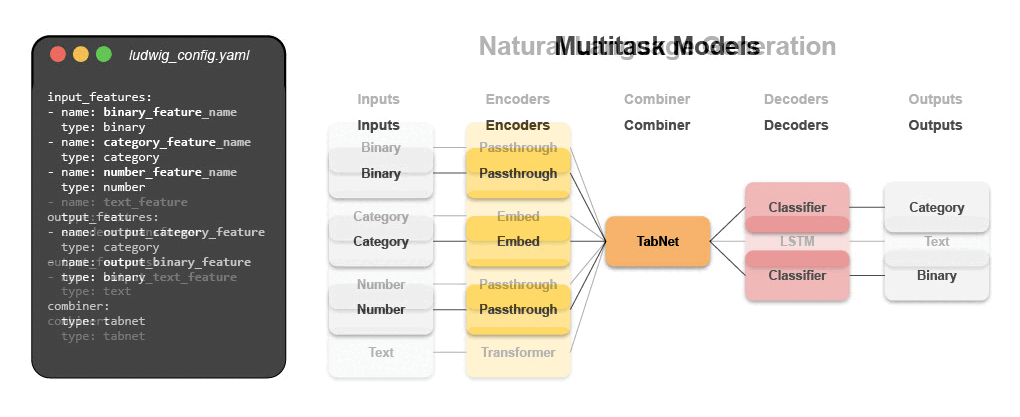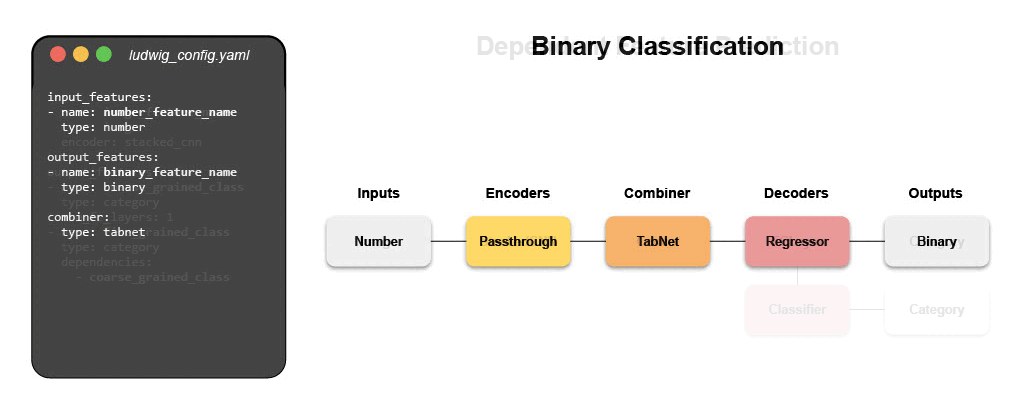
Take a look at Examples to see how you can use Ludwig for several many different applications.
Distributed training, data processing, and hyperparameter search with Ray¶
Ludwig on Ray enables users to scale their training process from running on their local laptop, to running in the cloud on a GPU instance, to scaling across hundreds of machines in parallel, all without changing a single line of code.
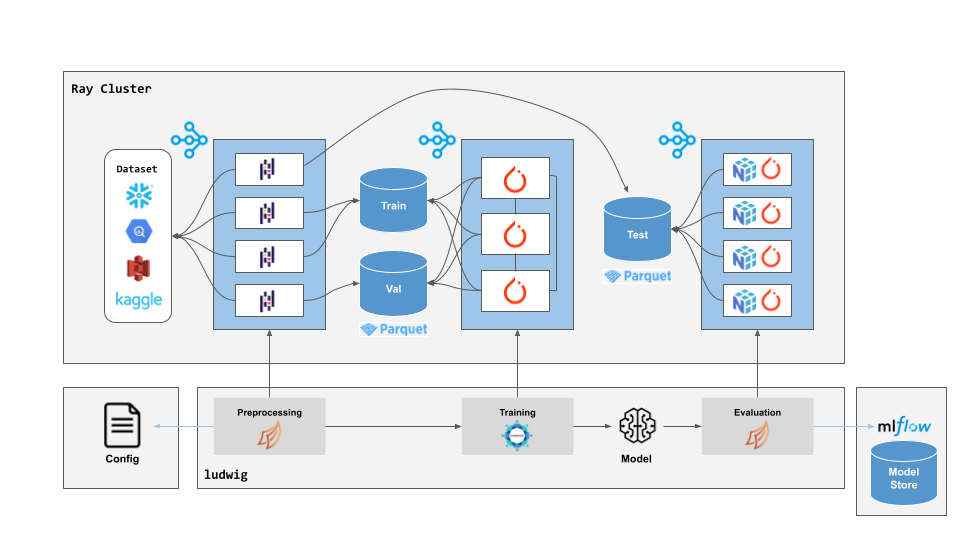
By integrating with Ray, Ludwig is able to provide a unified way for doing distributed training:
- Ray enables you to provision a cluster of machines in a single command through its cluster launcher.
- Dask on Ray enables you to process large datasets that don’t fit in memory on a single machine.
- Ray Tune enables you to easily run distributed hyperparameter search across many machines in parallel.